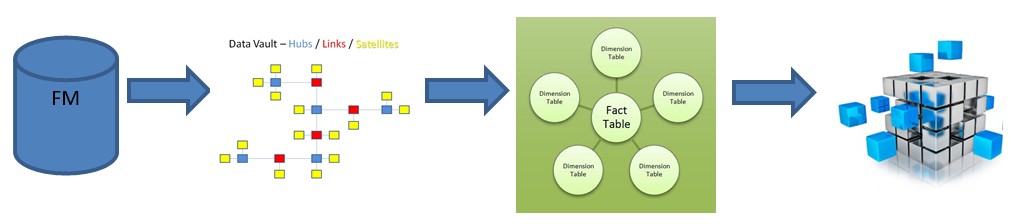
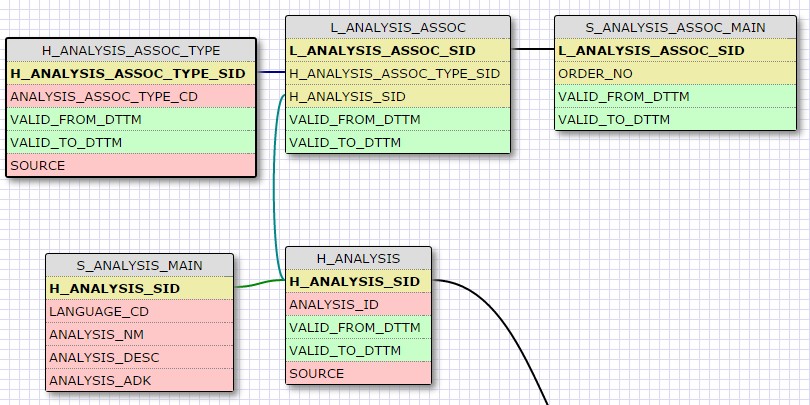
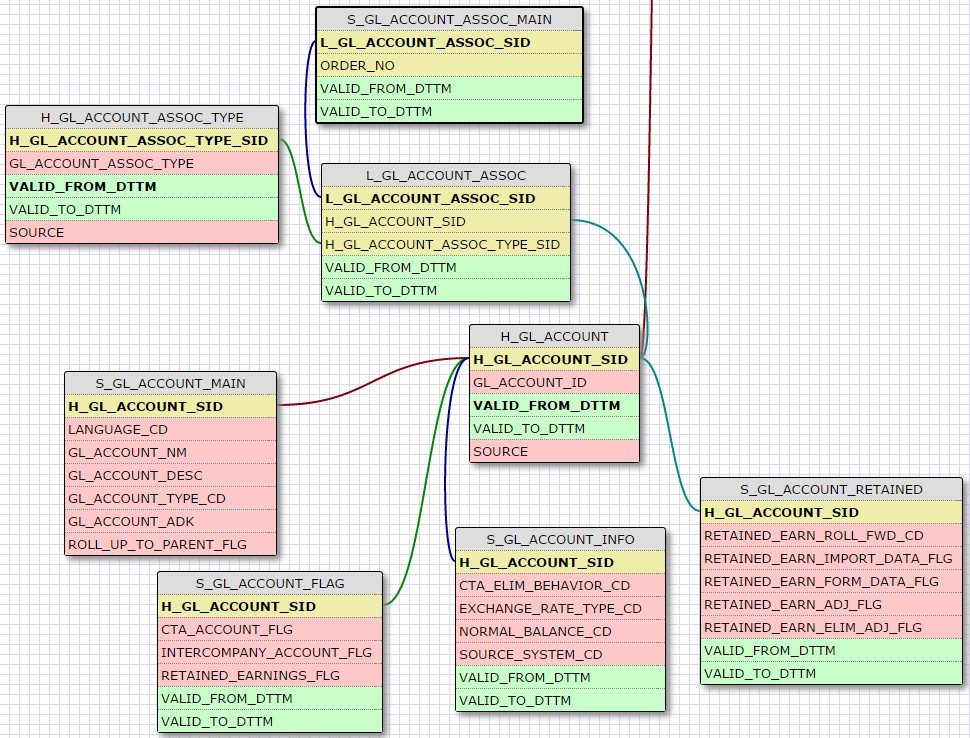
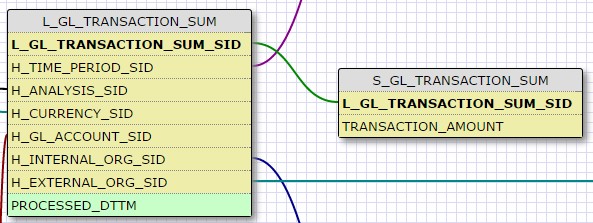
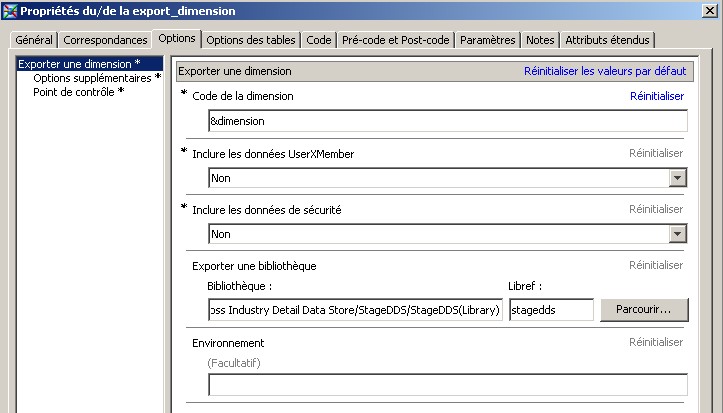
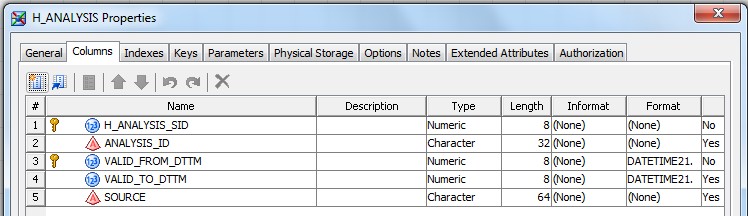
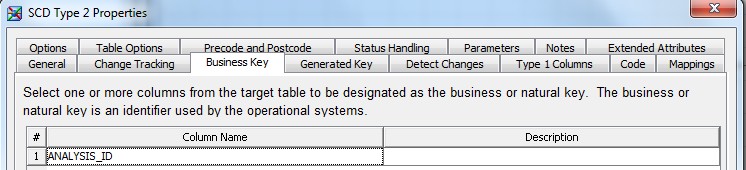
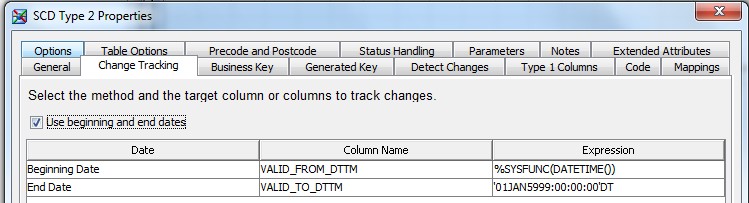
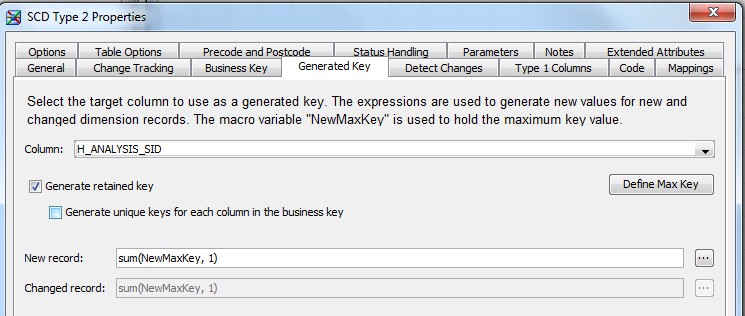
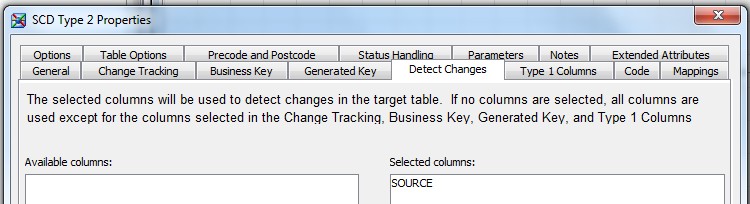
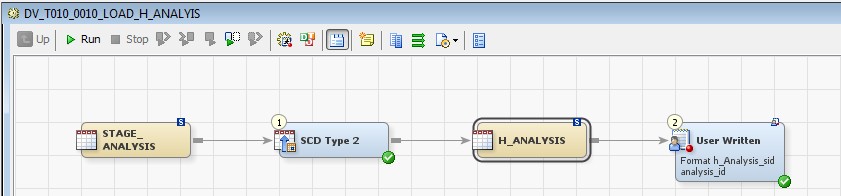
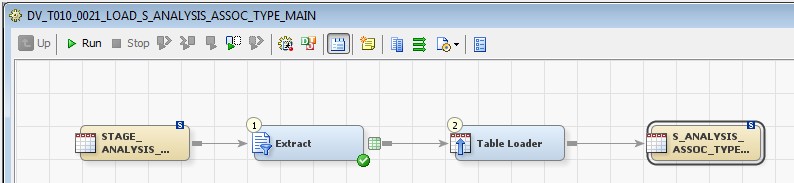
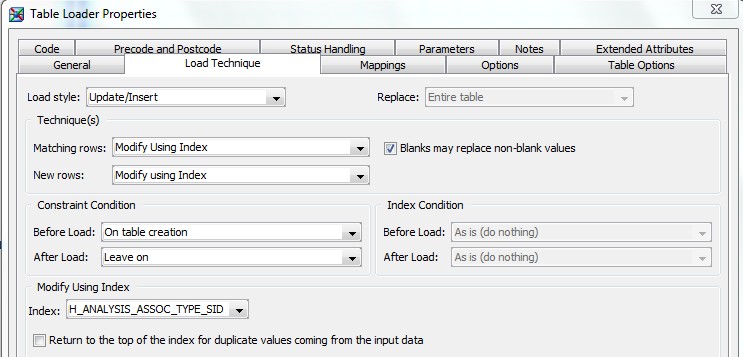
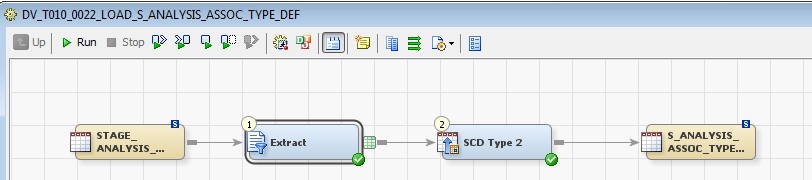
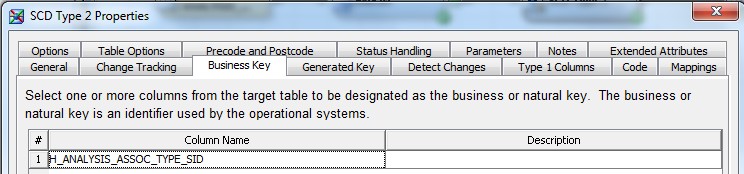
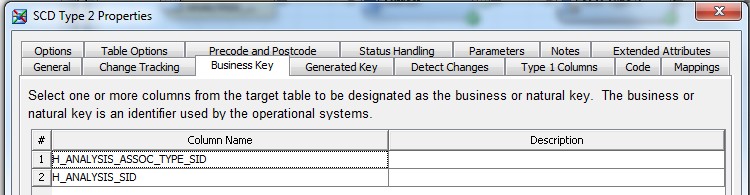
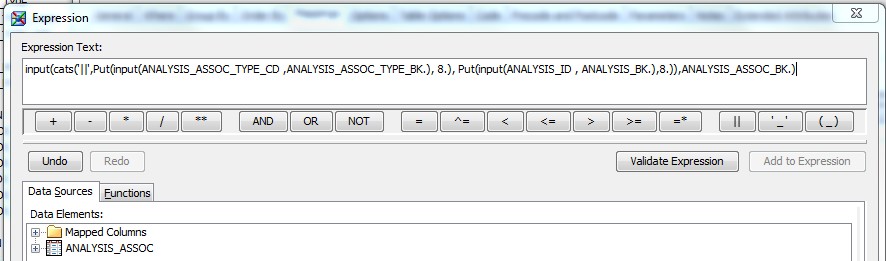
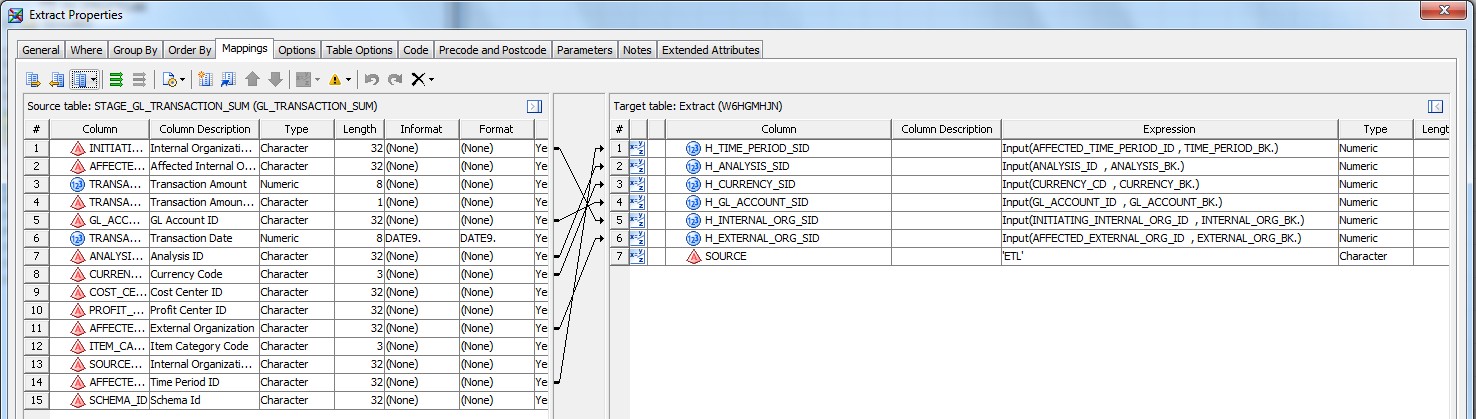
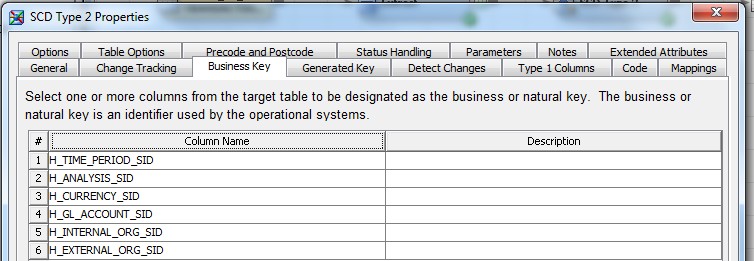
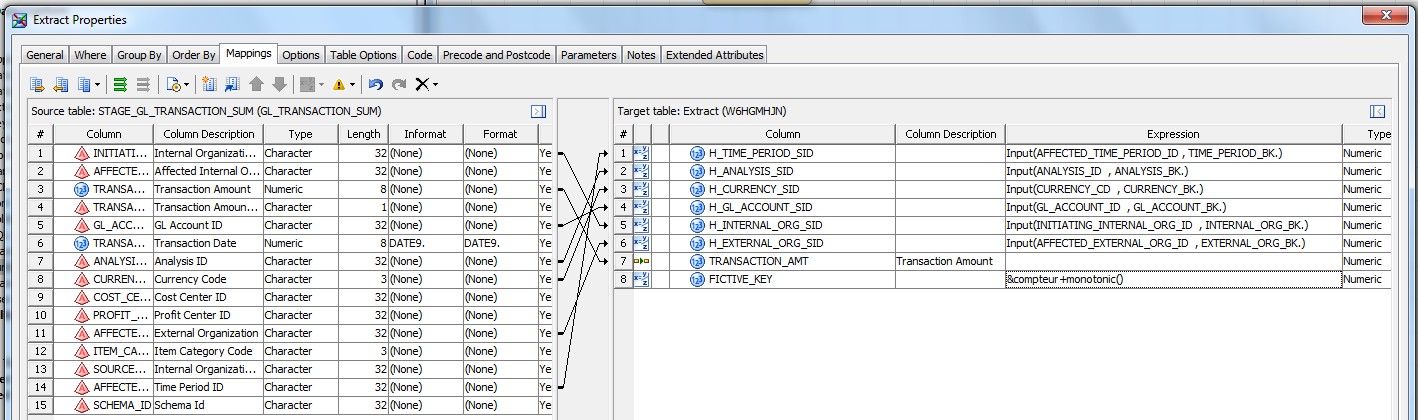
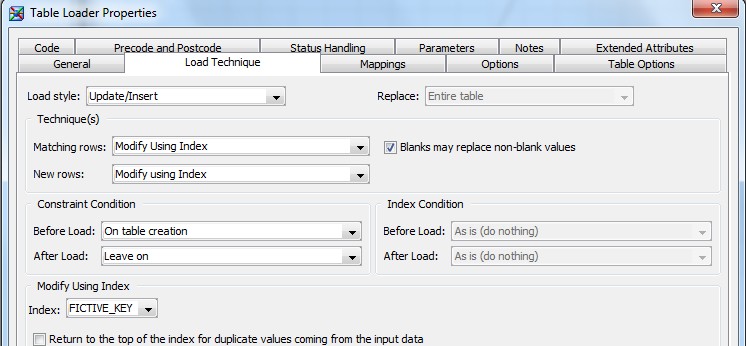
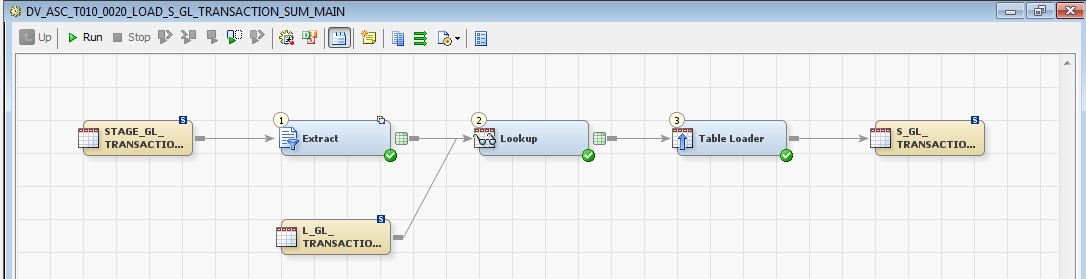
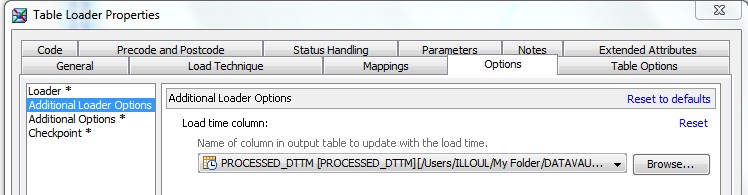
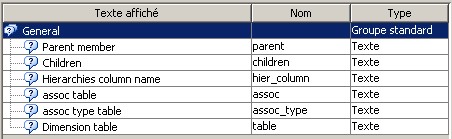
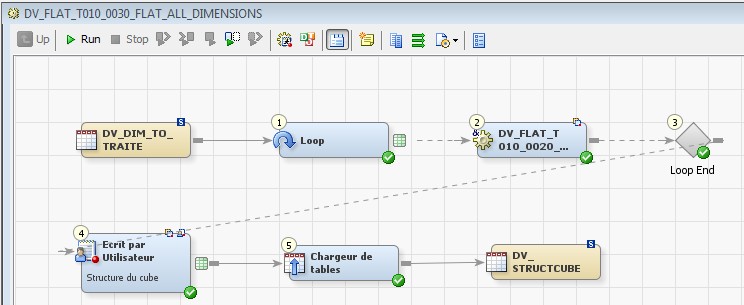
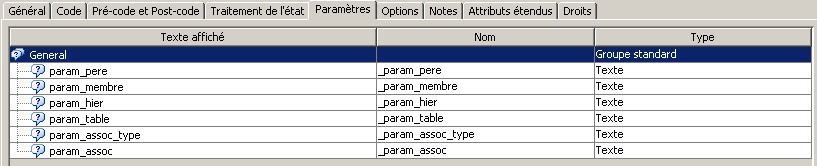
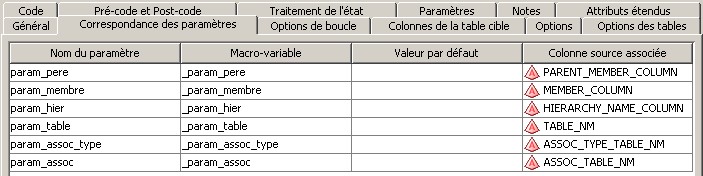
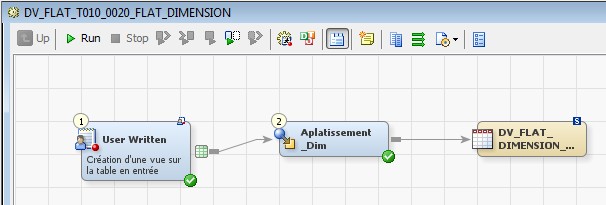
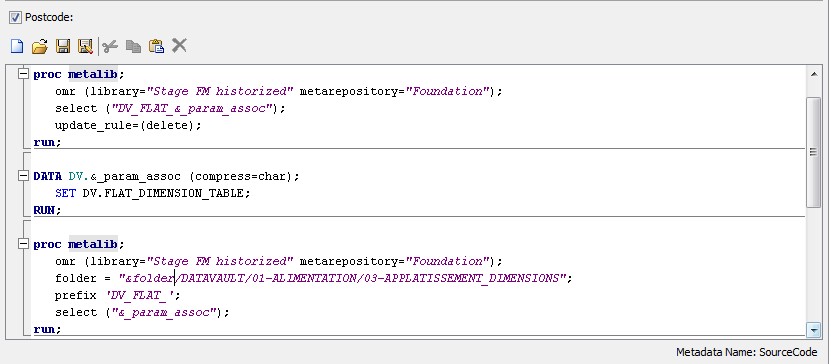
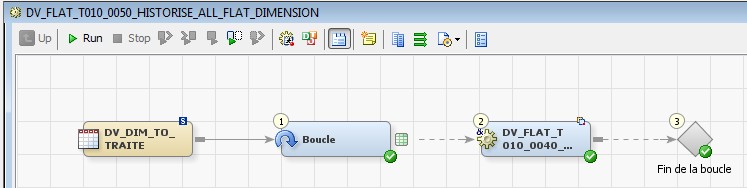
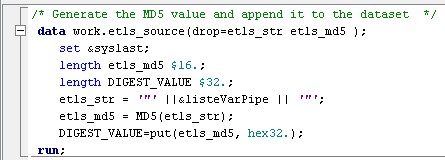
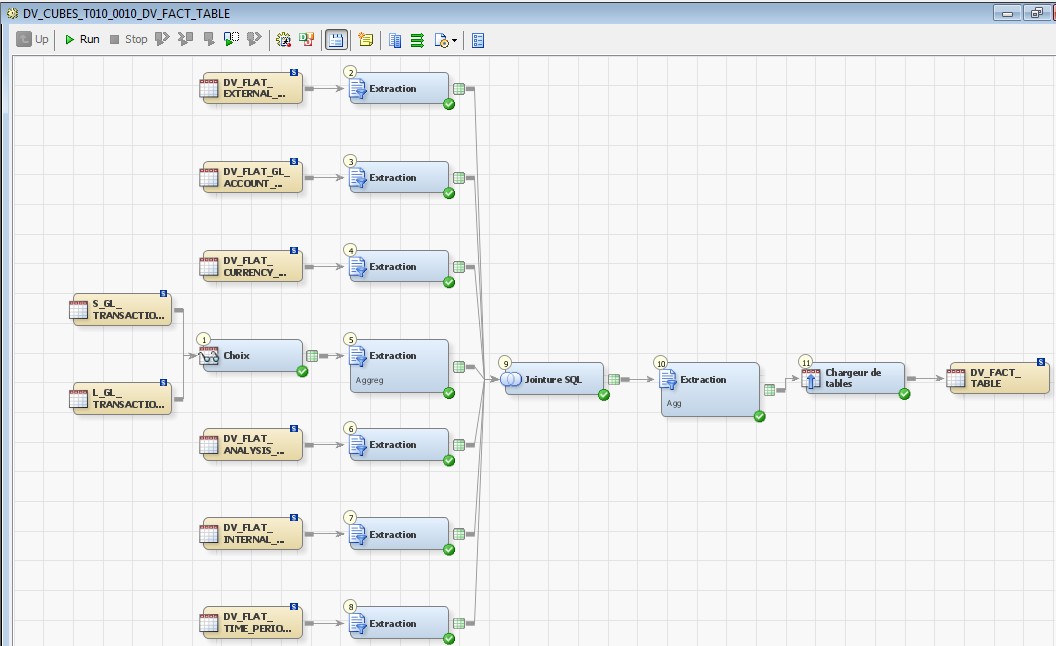
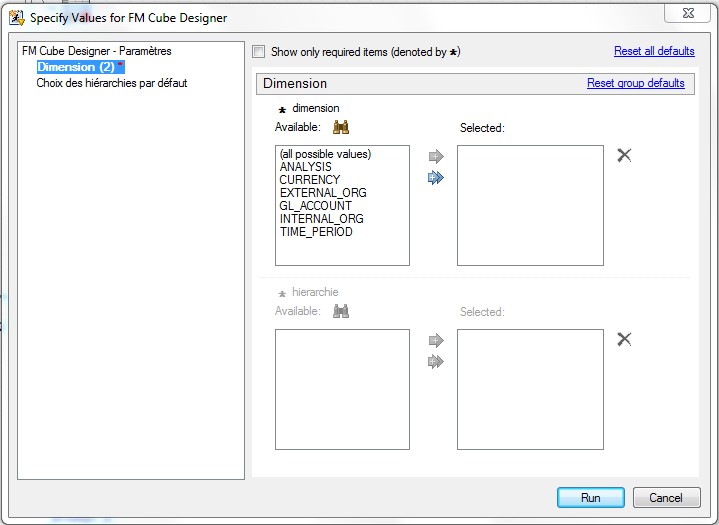
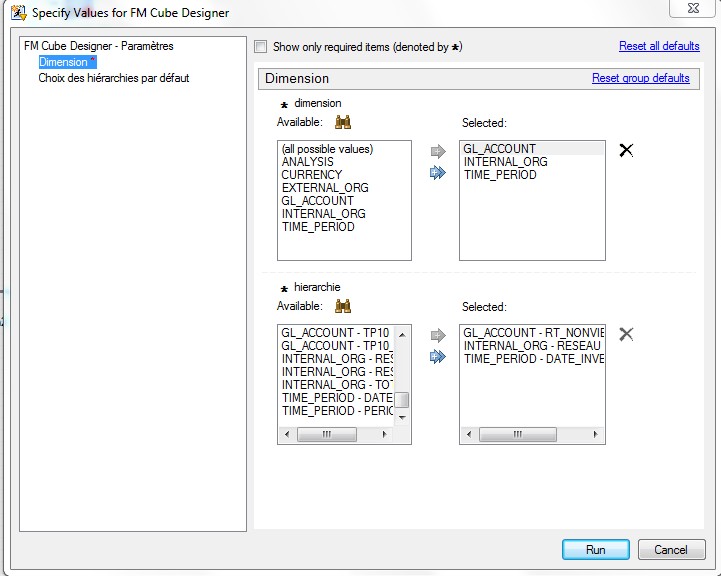
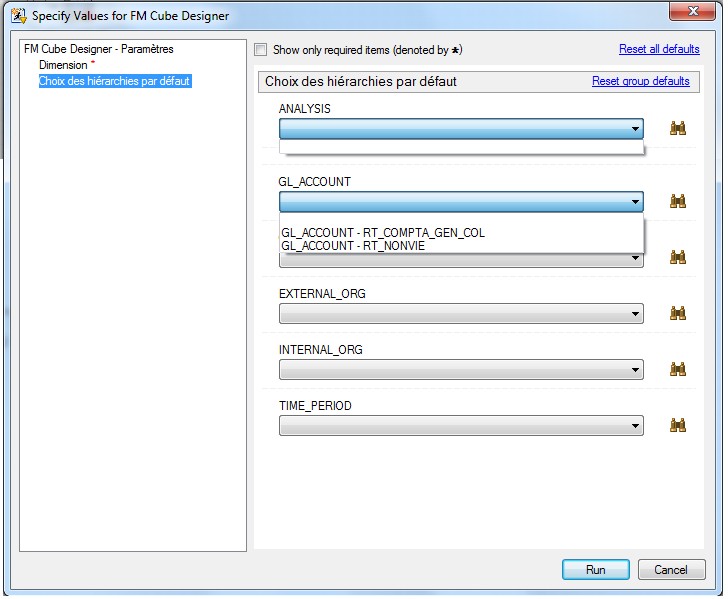
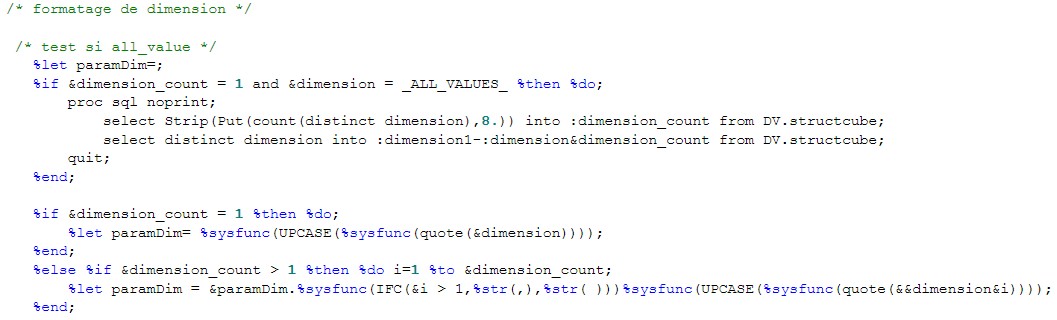
28 Déc 19 Cube OLAP à partir d'un modèle Data-Vault Le principe de la méthodologie de conception Data Vault est d’éclater les entités (au sens OLTP ou dimension en OLAP) en plusieurs morceaux : - Les hubs : Ils ne contiennent que les clés (clé de substitution et clé métier) ainsi que quelques métadonnées (dates de validité, origine, …) et aucun attribut. - Les satellites : Ils contiennent les attributs du hub. Chaque hub doit avoir au moins un satellite. Les attributs peuvent être regroupés dans des satellites selon leur nature, leur fréquence de mise à jour, … - Les liens : Ils permettent de relier plusieurs hubs. Ils ne contiennent que les clés des hubs ainsi que quelques métadonnées (dates de validité, origine, …) et une clé de substitution. Ils peuvent avoir optionnellement un ou plusieurs satellites. Le Data Vault présente plusieurs avantages : - Facilité pour retracer l’origine de la donnée. - Evolutivité peu onéreuse. De fait de l’isolation des attributs dans les satellites, peu de maintenance est nécessaire. - Rapidité de mise à jour. Du fait du découpage de l’entité, il est possible de mettre à jour seulement une partie de celle-ci. Même si depuis l'avénement des solutions in-memory les cubes OLAP sont de moins en moins utilisées, ils restent un excellent outil d'analyse. Pour illustrer mon propos, je vais créer un modèle en data-vault à partir du modèle interne de la solution SAS® Financial Management (SAS FM) puis créer un cube à partir de ce modèle. L’add-In SAS® Financial Management pour Microsoft Excel permet d’interroger les données SAS® Financial Management via un modèle. Cependant, un modèle ne permet de ne requêter qu’une seule hiérarchie par dimension. Ainsi, si l’on souhaite lors d’une analyse changer de hiérarchie, il faut créer un autre modèle. De plus, il n’est pas aisé avec ces rapports d’étudier l’évolution des données dans le temps. Les cubes OLAP permettent de s’affranchir de ces limites. Plusieurs étapes sont nécessaires pour arriver à notre but. Tout d’abord, il convient de créer un modèle de données capables d’historiser le modèle de données SAS® Financial Management. Ensuite, nous verrons les différentes stratégies d’alimentation de ce modèle. Enfin, nous créerons une application stockée permettant la génération du cube. Voici le schéma d’architecture globale : Modèle de données Présentation du modèle de données Dans SAS® Financial Management, chaque dimension dispose de trois tables : - Une table contenant la liste des membres ainsi que la valeur de leurs attributs ; - Une table contenant la liste des hiérarchies au sein de cette dimension ; - Une table contenant l’appartenance du membre à une hiérarchie. En Data Vault, les premières et troisièmes tables sont des hubs et la deuxième un lien entre ces deux tables. Voici ce que cela donne par exemple pour la dimension ANALYSIS : Comme nous souhaitons conserver l’historique, nous ajoutons les colonnes VALID_FROM_DTTM et VALID_TO_DTTM afin de définir la période de validité. Pour des dimensions plus complexes comme GL_ACCOUNT, il est intéressant de séparer les attributs dans plusieurs satellites afin de mettre à jour plus efficacement cette dimension : La table de fait (GL_TRANSACTION_SUM) devient une table de lien : Nous allons maintenant voir les différentes stratégies d’alimentation. Alimentation du modèle de données La solution SAS® Financial Management offre deux possibilités d’alimenter son modèle de données : - Avec le client SAS® Financial Management Studio. Ce dernier permet entres autres de créer des nouveaux membres, des hiérarchies, d’affecter des membres à une hiérarchie, d’importer et d’exporter des données, des dimensions. Cette alimentation est dite descendante. - En alimentant les tables Stage (par exemple avec SAS® Data Integration Studio) avant de charger dans SAS® Financial Management à l’aide d’applications stockées fournies par cette dernière solution. Cette alimentation est dite ascendante. Il n’est possible de n’exporter que les données d’un modèle depuis SAS® Financial Management, l’historisation de la table des faits GL_TRANSACTION_SUM se fait nécessairement de manière ascendante. En effet, un modèle ne peut avoir qu’une seule hiérarchie par dimension. Il faudrait donc de nombreux modèles pour couvrir l’ensemble des croisements des hiérarchies de chaque dimension. Alimentation descendante SAS® Financial Management fournit la transformation « export_dimension ». Elle attend en paramètre le nom de la dimension telle qu’elle est libellée dans le client SAS® Financial Management Studio. Afin de pouvoir paramétrer les dimensions que l’on souhaite exporter, nous allons créer une table de paramétrage dont les informations peuvent s’obtenir en grande partie à l’aide de la table DIMENSION_TYPE. Voici sa structure : - DIMENSION_CD : Nom de la dimension telle qu’elle est libellée dans le client SAS® Financial Management Studio. - TABLE_NM : Nom de la table StageDDS. - ASSOC_TABLE_NM : Nom de la table Assoc StageDDS. - ASSOC_TYPE_TABLE_NM : Nom de la table Assoc_Type StageDDS. - MEMBER_COLUMN : clé des tables TABLE_NM, ASSOC_TABLE_NM et ASSOC_TYPE_TABLE_NM. - PARENT_MEMBER_COLUMN : colonne PARENT des tables ASSOC. - HIERARCHY_NAME_COLUMN : colonne ASSOC_TYPE_CD des tables ASSOC. - BUSINESS_ID_COLUMN_NM: colonne BUSINESS_ID_COLUMN_NM de la table dimension_type. Voici un exemple de cette table : Afin de rendre cette tâche la plus dynamique possible, nous allons utiliser la transformation boucle. Cette dernière va se servir de la colonne TABLE_NM pour définir le paramètre dimension de la transformation « export_dimension ». Voici la vue du job : Voici les propriétés de la transformation boucle : Chaque modalité de la colonne DIMENSION_CD initialisera la valeur de la macro-variable dimension. Celle-ci sert de paramètre pour la transformation « export_dimension » : Alimentation du Data Vault Nous pouvons séparer l’alimentation du Data Vault selon la nature des entités (Hubs, satellites et liens). Alimentation des Hubs Prenons le cas de l’alimentation de la table H_ANALYSIS qui est le hub de la dimension ANALYSIS. Voici sa structure : ANALYSIS_ID est la clé de cette dimension dans la table StageDDS. Elle servira de clé métier (business key). Nous ajoutons une clé de substitution (surrogate key) qui prend la forme d’un entier auto-incrémenté. Ensuite, afin de garder l’historique des mouvements dans cette table, nous ajoutons les colonnes VALID_FROM_DTTM et VALID_TO_DTTM permettant de borner dans le temps la validité de la clé. Enfin, la colonne source permet de tracer l’origine de la donnée. Cette table a comme clé primaire la clé de substitution ainsi que VALID_FROM_DTTM. Afin de gérer la mise à jour, nous utilisons la transformation SCD2. La colonne ANALYSIS_ID nous sert de clé métier : Les colonnes VALID_FROM_DTTM et VALID_TO_DTTM servent aux suivis des changements : La transformation SCD2 s’occupe de l’incrémentation de la clé de substitution: Nous activons l’option Generate retained key avec nous voulons garder la même clé lorsqu’une nouvelle ligne est créée suite à la détection d’une modification. Sans cette option, une nouvelle clé serait calculée ce qui nous ferait perdre le lien avec les satellites et les liens. Enfin, la colonne source nous permet de détecter les changements : La clé de substitution sert de clé primaire les tables satellites et de clé étrangère pour les liens. Cependant, les données sources (tables StageDDS) contiennent les clés métiers. Afin de faciliter les transactions, nous créons un format qui associe ces deux clés. Voici une vue du job final : Alimentation des satellites La clé des tables satellites est la clé de substitution calculée dans les jobs des Hubs. Elle nous permet de gérer les mises à jour des tables satellites. Ces dernières peuvent être historisées ou non. Prenons l’exemple des satellites du hub H_ANALYSIS_ASSOC_TYPE qui gère les différentes hiérarchies de la dimension ANALYSIS. Ce hub dispose de deux tables satellites : - S_ANALYSIS_ASSOC_TYPE_MAIN contenant les informations décrivant chaque hiérarchie. Ces informations changeant très rarement et non indispensable à des fins d’analyse dans le temps il n’est pas nécessaire d’historiser les valeurs. - S_ANALYSIS_ASSOC_TYPE_DEF contenant la valeur par défaut de chaque hiérarchie. Il peut être intéressant de conserver les différentes modalités au cours du temps. Cinématique du traitement : 1- La clé de substitution est déterminée à partir de la clé business (pour cet exemple ANALYSIS_ASSOC_TYPE_CD) à partir du format créé dans le job du Hub. 2- La transformation SCD 2 ou chargeur de table – Mise à jour à partir de l’index se charge de la mise à jour de la table. Voici la vue finale du job gérant la table S_ANALYSIS_ASSOC_TYPE_MAIN : La transformation « extract » permet de déterminer la clé de substitution: Et la transformation « Table loader » se charge de la mise à jour : Voici la vue finale du job gérant la table S_ANALYSIS_ASSOC_TYPE_DEF : La transformation « extract » permet de déterminer la clé de substitution: Et le SCD 2 se charge de la mise à jour : Alimentation des links Les links font les liens entre plusieurs hubs : il faut donc les alimenter une fois les hubs concernés traités. Dans notre cas, il s’agit des tables ASSOC qui font le lien entre les membres et les hiérarchies permettant ainsi de voir l’appartenance d’un membre à une hiérarchie ainsi que le lien père-fils. Cinématique du traitement : 1- Extraction des données nécessaires à partir de la table STAGE_ASSOC. 2- Détermination des clés de substitution (celle du membre fils et celle de la hiérarchie) à partir des formats créés dans les jobs des hubs. 3- SCD 2 pour déterminer les mises à jour. Voici la vue finale par exemple pour le link L_ANALYSIS_ASSOC : La transformation « extract » permet de déterminer les clés de substitution : Et la transformation SCD 2 se charge de la mise à jour : Les satellites des links s’alimentent de la même façon que ceux des hubs ; la détermination de la clé de substitution est juste plus complexe : Voici l’expression complète pour la détermination de la clé de substitution: Alimentation ascendante Les tables STAGE s’alimentent de la même manière que lors d’un projet SAS FM standard ; nous ne détaillerons pas ici cette étape. Cependant, comme spécifié plus haut, l’intégration de la table de faits dans ce modèle ne peut se faire que par alimentation ascendante. La table des faits n’est qu’un lien entre les dimensions et elle fournit une valeur à ce croisement. En Data Vault, cette table prend la forme d’un link ; la valeur sera renseignée dans une table satellite de ce link. La cinématique de traitement de ce link est semblable aux autres links : La transformation « extract » permet le calcul des clés de substitutions : Et la transformation SCD 2 se charge de la mise à jour selon la clé métier : La table satellite de la table de fait contient cependant une subtilité. En effet, les systèmes sources peuvent nous apporter plusieurs valeurs pour un même croisement. Si dans SAS FM le résultat sera agrégé, pour des fins d’audit, nous souhaitons conserver ces différentes occurrences. Nous ne pouvons utiliser la surrogate clé du link de la table de fait. Nous devons créer une clé fictive. Dans SAS Data Integration, la transformation Chargeur de table – mise à jour avec Index ne gère pas les clés de substitution automatiquement. Nous devons donc l’implémenter. Pour cela, nous stockons la valeur de la dernière clé dans une table que l’on interrogera pour retrouver cette valeur. Celle-ci sera incrémentée pour chaque nouveau fait puis de nouveau stockée. Voici une capture d’écran résumant cette étape : La macro-variable compteur contient la valeur de la dernière clé et la fonction monotonic() renvoie le numéro de l’itération. Après cette étape, nous récupérons la surrogate key du link par une transformation lookup puis une transformation Chargeur de table – mise à jour avec Index se charge de la mise à jour du satellite : Voici la vue finale de ce job : La table satellite contient non seulement les faits mais aussi la date de traitement qui permettra de retrouver le croisement des dimensions qui a introduit ces faits : Nous venons de voir l’alimentation du Data Vault. Nous allons maintenant passer à l’alimentation du modèle en étoile qui permettra la génération des cubes. Alimentation du modèle en étoile Les dimensions SAS® Financial Management sont stockées dans les tables StageDDS sous forme fils - père. Il n’est pas aisé de créer un cube à partir d’un tel stockage. Il est donc nécessaire afin de pouvoir créer des cubes de les aplatir ; c’est-à-dire de créer une colonne par niveau de hiérarchie. Aplatissement des dimensions Pour aplatir les dimensions, nous allons créer une nouvelle transformation. Celle-ci générera en sortie une table aplatie et attend ces paramètres : Afin de dynamiser cette étape, nous allons créer une boucle qui se base sur la table de paramétrage des dimensions. Voici une vue de ce job : La phase d’aplatissement est isolée dans un job à paramètre. Voici ces paramètres : La boucle doit donc initialiser ces paramètres : Voici la vue du job d’aplatissement : La première étape crée une vue à partir de la table Assoc (paramètre _param_assoc). La transformation génère une table générique qui alimentera la table cible. Les métadonnées de cette dernière sont automatiquement mises à jour à la fin du job : La table STRUCTCUBE en sortie du job principal contient pour chaque dimension choisie les hiérarchies et leurs niveaux. Elle servira à générer les cubes. Etapes de la transformation aplatissement : 1. Récupération de l’ensemble des hiérarchies de la dimension en paramètre à partir de la table Assoc_Type. 2. Pour chaque hiérarchie, on récupère les membres. Il y a deux cas de figure : a. Les membres rattachés directement à la racine. Pour les récupérer, il faut garder les lignes dont le père et le fils sont identiques. Le père est mis à blanc. b. Les autres membres. 3. On part des dernières feuilles de la hiérarchie. Pour identifier ces feuilles, il faut prendre les membres qui ne sont jamais père, c’est-à-dire qu’ils n’apparaissent jamais dans la colonne père. 4. A partir de la table des membres, on boucle pour remonter dans la hiérarchie (le père devient le fils dans l’itération suivante). C’est pour ceci qu’il est important de mettre à blanc le père des membres rattachés à la racine car sinon la boucle serait infinie. 5. La table obtenue part du niveau le plus profond dans la hiérarchie vers la racine. Il convient alors d’inverser les colonnes. 6. L’ensemble des tables obtenues est fusionné dans une seule table donc la clé est le membre. Elle est nommée MEMBER_ID afin de l’uniformiser pour l’ensemble des dimensions. 7. Nous récupérons grâce à la clé les attributs des dimensions le cas échéant. 8. Nous récupérons pour chaque hiérarchie l’order_no. Ainsi nous avons une colonne order_no par hiérarchie ce qui permettra d’avoir les membres classés dans le même ordre dans le cube que dans SAS® Financial Management. Voici un exemple : Historisation des tables aplaties : Lorsque l’on exporte les dimensions depuis SAS® Financial Management, nous n’avons que la vue actuelle des dimensions. Cependant, pour des questions d’analyse, nous voudrions conserver l’évolution des dimensions au fil du temps. Il convient alors d’historiser les tables aplaties à l’aide de la transformation SCD2. Afin de dynamiser le traitement en fonction des dimensions souhaitées, nous allons utiliser une boucle qui se base sur la table de paramètre. Voici une vue du job : La boucle prend comme paramètre la table Assoc de la dimension : Voici le diagramme du job contenant le SCD2 : La table FLAT_TEMPLATE est chargée avec le contenu de la table Assoc passée en paramètre. Il convient donc de mettre à jour ces métadonnées avant le SCD2. La profondeur de chaque hiérarchie peut évoluer. Ainsi, de nouveaux niveaux peuvent apparaître; d’autres disparaître. En préalable du SCD 2, il convient tout d’abord d’harmoniser les colonnes en entrée et en sortie. Les colonnes présentes dans FLAT_TEMPLATE mais non présente dans FLAT_TEMPLATE_H sont rajoutées dans cette dernière et inversement. La clé métier dans le SCD2 est la clé MEMBER_ID. Une fois la transformation paramétrée, il convient de modifier ce code afin de dynamiser la détermination de la colonne etls_md5 servant à la détection des modifications. Il suffit de récupérer les colonnes qui ne sont ni clés, ni « suivi des modifications » : Puis de modifier le code automatique générée qui détermine la colonne etls_md5 comme suit : Les tables de dimensions ont été traitées, il ne reste plus que la gestion de la table de fait. 2. Gestion de la table de fait La difficulté pour cette étape est de récupérer pour chaque fait le croisement des dimensions au moment de sa création. Les tables aplaties d’historique permettent de retrouver cette information. Cependant, la clé de cette table est MEMBRE_ID et VALID_FROM_DTTM. Or dans la table de fait la référence à la dimension se fait seulement avec une colonne. Nous devons donc créer pour chaque table de dimension aplatie une clé fictive. Cinématique du traitement : - Les faits sont stockés dans la table S_GL_TRANSACTION_SUM_MAIN. Grâce à la colonne L_FACT_TABLE_ID, nous pouvons récupérer à partir de la table link L_GL_TRANSACTION_SUM les clés de chaque hub des dimensions. - Agrégation de la table obtenue. A ce niveau, il n’est plus nécessaire de garder le détail de chaque transaction. - Calcul d’une clé fictive pour chaque table aplatie d’historique. - Construction de la table de fait. Celle-ci sera composée du croisement des clés fictives et des faits. Pour récupérer les clés fictives, nous faisons une jointure entre la table agrégée obtenue plus haut et les tables aplaties d’historique dotées de la clé fictive ; la clé de jointure étant la clé de chaque hub et la validité de cette clé au moment de l’introduction du fait. Par exemple pour la dimension ANALYSIS cela donne : _FACT.H_ANALYSIS_SID = _HUB.H_ANALYSIS_SID and _FACT.PROCESSED_DTTM BETWEEN _HUB.VALID_FROM_DTTM AND _HUB.VALID_TO_DTTM - Agrégation des faits par clé fictive récupérée. Voici la vue finale du job : Le modèle en étoile a été alimenté. Les cubes peuvent être générés à partir de celui-ci. Génération des cubes à la demande La fonctionnalité permettant la génération à la volée du cube doit respecter le cahier des charges suivant : - Choisir les dimensions que l’on souhaite analyser. - Pour chaque dimension choisie, l’utilisateur pourra choisir les hiérarchies. - Si l’utilisateur choisit plusieurs hiérarchies pour une même dimension, il devra choisir une hiérarchie principale d’affichage. Il existe une limitation à ce process : l’ordre d’affichage des membres d’une hiérarchie telle qu’on la voit dans SAS FM Studio ne peut être garanti que pour une seule hiérarchie. Si, au cours de l’exploitation du cube, on souhaite changer de hiérarchie l’ordre de cette dernière ne pourra être identique à celui que l’on voit dans SAS FM Studio. Cette limitation provient du fait que SAS se base sur la table source pour construire et afficher le cube et cette dernière ne permet pour une colonne qu’un seul ordre de tri. - Les membres calculés créés dans SAS FM Studio qui n’apparaissent pas dans les tables STAGE des dimensions mais dans la table STAGE APP_FORMULA doivent être repris dans le cube. Cette fonctionnalité a été implémentée par une application stockée SAS. Le choix des dimensions, hiérarchies et de la dimension principale d’affichage est implémentée par le prompt framework. L’écran suivant est affiché au lancement de l’application stockée : Tant que l’on ne choisit pas de dimensions, l’écran ne permet pas de choisir de hiérarchie. Une fois les dimensions choisies, il est possible de choisir les hiérarchies : Le choix des hiérarchies principales n’est possible que pour les dimensions choisies : Une fois cet écran validé, le processus de génération du cube est lancé. Cinématique du traitement : - La première phase du traitement se charge de reformater les éléments envoyés par l’écran précédent afin de pouvoir requêter la table structcube. Ces éléments sont reçus sous forme de macros-variables. Il y a autant de macros-variables créées que d’éléments choisis. S’il n’y a qu’un élément la macro-variable portera le même nom que le nom du champ de l’écran ; s’il y en a plusieurs alors leur nom sera suivi un numéro. Par exemple pour les dimensions le nom du champ de l’écran est dimension. L’application stockée recevra une macro-variable dimension pour le cas où une seule dimension a été choisie et dimension1, dimension2, … dimensionN si plusieurs dimensions ont été choisies. Une autre macro-variable contenant le nombre d’éléments est créée. Elle porte le nom du champ de l’écran suffixé par _count. Par exemple pour dimension nous avons dimension_count. Pour le cas particulier du choix « toutes valeurs possibles », l’application stockée reçoit cette modalité ainsi que 1 pour le nombre d’éléments et non pas la liste complète. Il convient alors de faire un traitement particulier pour ce cas : nous prenons la liste complète des dimensions à partir de table structcube. Voici par exemple la gestion du reformatage pour le champ dimension : Il existe d’autres cas limites. Par exemple si l’on ne spécifie pas les hiérarchies que l’on souhaite pour une dimension que l’on a choisie. Dans ce cas, le choix a été fait de prendre l’ensemble des hiérarchies de cette dimension. - A partir de ce reformatage et de la table structcube, nous récupérons la liste des niveaux de chaque hiérarchie. Celles-ci sont stockées dans des macros-variables dont le nom fait référence à la notion qui l’englobe : niveau est englobé dans hiérarchie elle-même englobée dans dimension ce qui permet à partir d’une dimension de retrouver ses hiérarchies et pour ces hiérarchies de retrouver ces niveaux. - Les tables aplaties des dimensions concernées sont copiées. Seules les colonnes des hiérarchies demandées sont conservées. - Pour chaque membre est déterminées sa formule SAS FM et sa formule MDX. La formule SAS FM est du type ["nom de la dimension" = "valeur du membre"]. Sa formule MDX dépend du nombre de hiérarchie. S’il n’y en a qu’une seule alors la formule MDX est du type : [nom de la dimension].[All nom de la hiérarchie].[ valeur du membre] S’il y en a plusieurs, elle est du type : [nom de la dimension].[All nom de la hiérarchie].[ valeur du membre] [nom de la dimension].[nom de la hiérarchie].[All nom de la hiérarchie].[valeur du membre] La formule MDX étant différente pour chaque hiérarchie, elle est déterminée pour chaque hiérarchie. L’association entre la formule SAS FM et sa formule MDX permettra de créer les membres calculées. - Les membres calculés sont extraits à partir de la table APP_FORMULA pour les dimensions concernées. Chacune de ces formules est analysée grammaticalement à l’aide d’une expression rationnelle afin de trouver et d’extraire les différents opérandes de la formule et les remplacer par la formule MDX adéquate. Le motif suivant est utilisé : /[ /\[""%sysfunc(strip(&dim))""=""[A-Z_0-9]+""\]/i - Les tables aplaties copiées sont enregistrées en métadonnées car SAS ne peut créer de cube qu’à partir de tables enregistrées en métadonnées. - La procédure « Proc OLAP » est générée dynamiquement à partir des différents éléments récoltés (dimensions, hiérarchies, niveaux, membres calculés, …). Voici un résultat exemple : Optimisation : Afin d’accélérer la consultation du cube, la détermination à la volée des combinaisons des croisements permettant la création d’agrégation a été implémentée. Une nouvelle colonne top_to_tune a été rajoutée dans la table DIM_TO_TRAITE afin de déterminer si la dimension est à optimiser ou non. La détermination à la volée des combinaisons des croisements est implémentée à l’aide de l’algorithme binary counting : 1. Création d’une variable qui concatène les hiérarchies. Exemple : si l’on a choisi les hiérarchies GL_ACCOUNT, ANALYSIS et TIME, cette variable aura comme valeur GL_ACCOUNT|ANALYSIS| TIME. 2. Création d’une variable binaire qui permet de déterminer quelle partie de la variable créée en 1 prendre. Il y a autant de bit que de hiérarchie. Les différentes valeurs de cette variable sont générées par cette formule : DO i=0 TO 2**(X-1); BINARY_COUNTER = i; END; avec x le nombre de hiérarchie choisie. Pour chaque itération, on efface de la variable créée en 1 la hiérarchie dont la valeur binaire est 0. Example: Ce qui nous donne : Voila nous venons de convertir un modèle OLTP vers un modèle Data-Vault pour ensuite créer des cubes dynamiques à partir de ce dernier.